

Amazon SageMaker AI đã liên tục giảm độ trễ trong các giai đoạn mở rộng quy mô này: phát hiện nhu cầu mở rộng quy mô, cấp phát phiên bản, tải xuống hình ảnh container, lấy trọng số mô hình và khởi động container. Trước đây, Amazon SageMaker AI đã giới thiệu các chỉ số Amazon CloudWatch dưới một phút để giúp phát hiện nhu cầu mở rộng quy mô nhanh hơn tới 6 lần so với các cơ chế truyền thống và ra mắt giải pháp bộ nhớ đệm dữ liệu thành phần suy luận , lưu trữ hình ảnh container và các tạo phẩm mô hình trên các phiên bản đang chạy. Cách tiếp cận này đã giảm độ trễ khởi động nguội cho các hoạt động mở rộng quy mô thành phần suy luận sử dụng lại các phiên bản hiện có. Cùng nhau, các tính năng này đã cải thiện khả năng phản hồi tự động mở rộng quy mô cho các trường hợp mà thành phần suy luận có thể được đặt trên một phiên bản đã được cấp phát và sử dụng bộ nhớ đệm hiện có.
Với bộ nhớ đệm container, Amazon SageMaker AI mở rộng những cải tiến về khả năng mở rộng này đến các trường hợp cần khởi chạy các phiên bản mới. Bộ nhớ đệm container loại bỏ độ trễ khi tải xuống hình ảnh container ngay cả khi cần khởi chạy các phiên bản mới, trường hợp mà bộ nhớ đệm dựa trên kho lưu trữ phiên bản trước đây của chúng tôi không thể giải quyết được. Trong bài viết này, chúng tôi sẽ trình bày cách bộ nhớ đệm container giải quyết nút thắt cổ chai khi tải xuống hình ảnh container và chứng minh những cải tiến về hiệu suất mà bạn có thể mong đợi.
1.Thách thức về khả năng mở rộng: Khi cần khởi chạy các phiên bản mới
Sơ đồ sau đây minh họa các bước trong quá trình mở rộng quy mô phiên bản khi khởi chạy một phiên bản mới.
- Cấp phát phiên bản: Phiên bản Amazon Elastic Compute Cloud ( Amazon EC2 ) mới được khởi chạy.
- Tải ảnh container: Ảnh container được tải từ Amazon Elastic Container Registry ( Amazon ECR ).
- Tải xuống các thành phần mô hình: Trọng số mô hình được lấy từ Amazon Simple Storage Service ( Amazon S3 ).
- Khởi động container và kiểm tra trạng thái: Máy chủ suy luận khởi tạo, tải mô hình vào bộ nhớ và vượt qua các bước kiểm tra sẵn sàng.
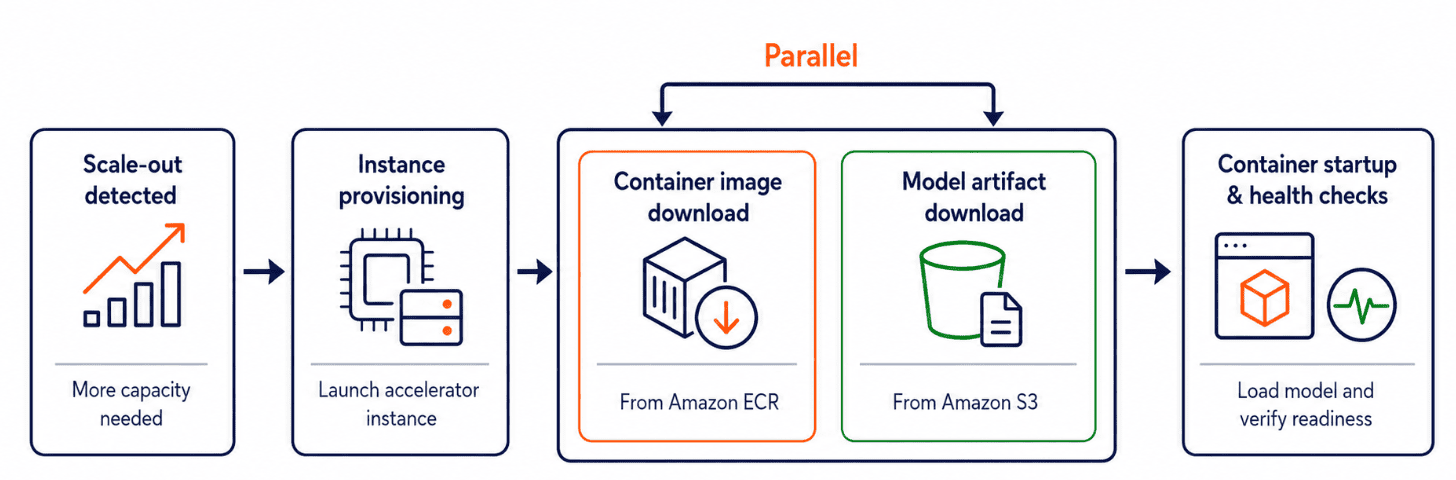
Lưu ý : Quá trình tải xuống ảnh container và tải xuống các thành phần mô hình diễn ra song song.
Việc tải xuống ảnh container thường là nguyên nhân chính gây ra độ trễ khi mở rộng quy mô điểm cuối, đặc biệt đối với các khối lượng công việc AI tạo sinh. Các khối lượng công việc này sử dụng các container lớn như SageMaker Large Model Inference (LMI, được hỗ trợ bởi vLLM), vLLM và NVIDIA Triton. Việc lưu trữ container vào bộ nhớ cache giúp loại bỏ bước tải ảnh container trong các sự kiện mở rộng quy mô phiên bản mới đối với các mẫu điểm cuối phổ biến:
- Các điểm cuối mô hình đơn lẻ – Việc mở rộng quy mô được thực hiện bằng cách khởi chạy thêm các phiên bản, mỗi phiên bản lưu trữ một bản sao riêng của mô hình.
- Các điểm cuối dựa trên thành phần suy luận – Việc mở rộng quy mô chỉ thêm các phiên bản mới khi không có phiên bản hiện có nào đủ dung lượng để chứa thêm một thành phần suy luận.
2. AI Model Scaling
Hình ảnh sau đây cho thấy cách thức thay đổi tiến trình mở rộng quy mô cho mô hình Qwen3-8B (16 GB) trên một phiên bản ml.g6.2xlarge sử dụng vùng chứa LMI (17,7 GB sau khi nén).
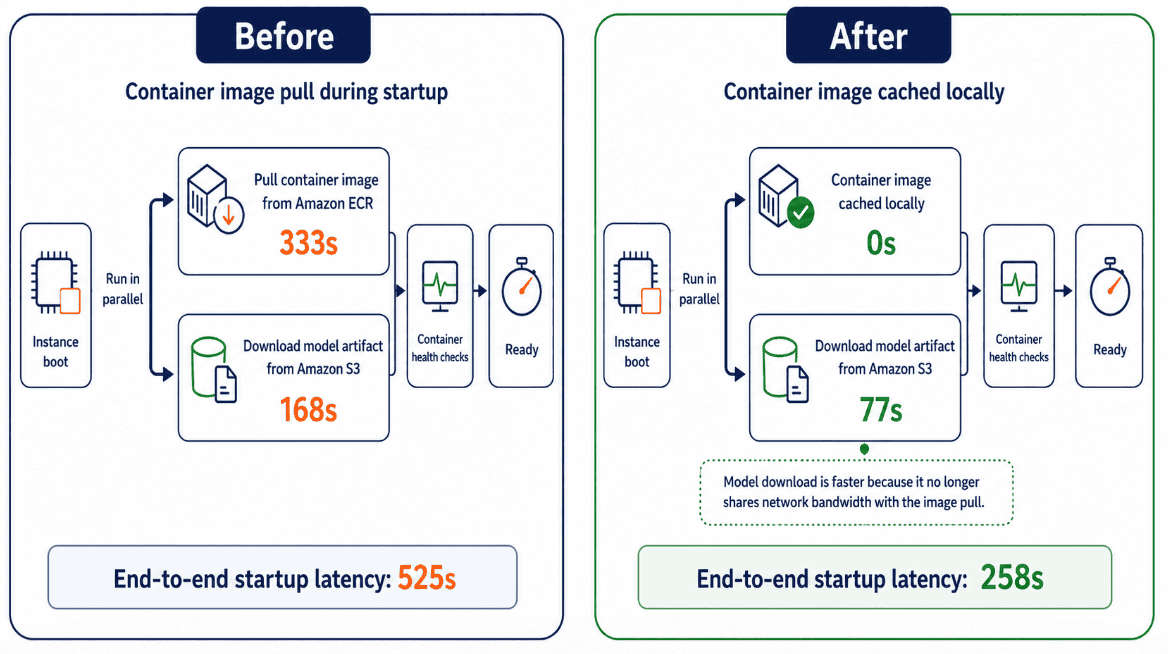
Trước khi sử dụng bộ nhớ đệm container:
- Tải ảnh container từ Amazon ECR: 333 giây
- Thời gian tải xuống mô hình từ Amazon S3: 168 giây
Quá trình tải ảnh và tải mô hình diễn ra song song, do đó độ trễ khởi động từ đầu đến cuối là 525 giây.
Sau khi lưu vào bộ nhớ đệm container:
- Ảnh container đã được lưu vào bộ nhớ cache cục bộ: 0 giây
- Thời gian tải xuống mô hình : 77 giây. Với việc hình ảnh container được lưu vào bộ nhớ cache trước, quá trình tải xuống mô hình không còn cạnh tranh băng thông mạng với quá trình tải hình ảnh, giảm độ trễ từ 168 giây xuống còn 77 giây.
Độ trễ khởi động từ đầu đến cuối giảm xuống còn 258 giây.
Kết quả: Việc lưu trữ container vào bộ nhớ đệm giúp loại bỏ việc tải ảnh khỏi quy trình mở rộng quy mô và giảm thiểu xung đột băng thông mạng, giảm độ trễ khởi động từ đầu đến cuối từ 525 giây xuống còn 258 giây, cải thiện khoảng 51%. Nếu ảnh được lưu trong bộ nhớ đệm không khả dụng, SageMaker AI sẽ tự động chuyển sang tải ảnh từ Amazon ECR, do đó việc mở rộng quy mô không bao giờ bị chặn.
2.1. Cách thức hoạt động của bộ nhớ đệm container với các thành phần suy luận
Bộ nhớ đệm container hoạt động với các thành phần suy luận. Khi bạn triển khai nhiều thành phần suy luận, bộ nhớ đệm sẽ lưu trữ từng hình ảnh container duy nhất được các thành phần suy luận của bạn tham chiếu đến.
2.2. Security and tenant isolation
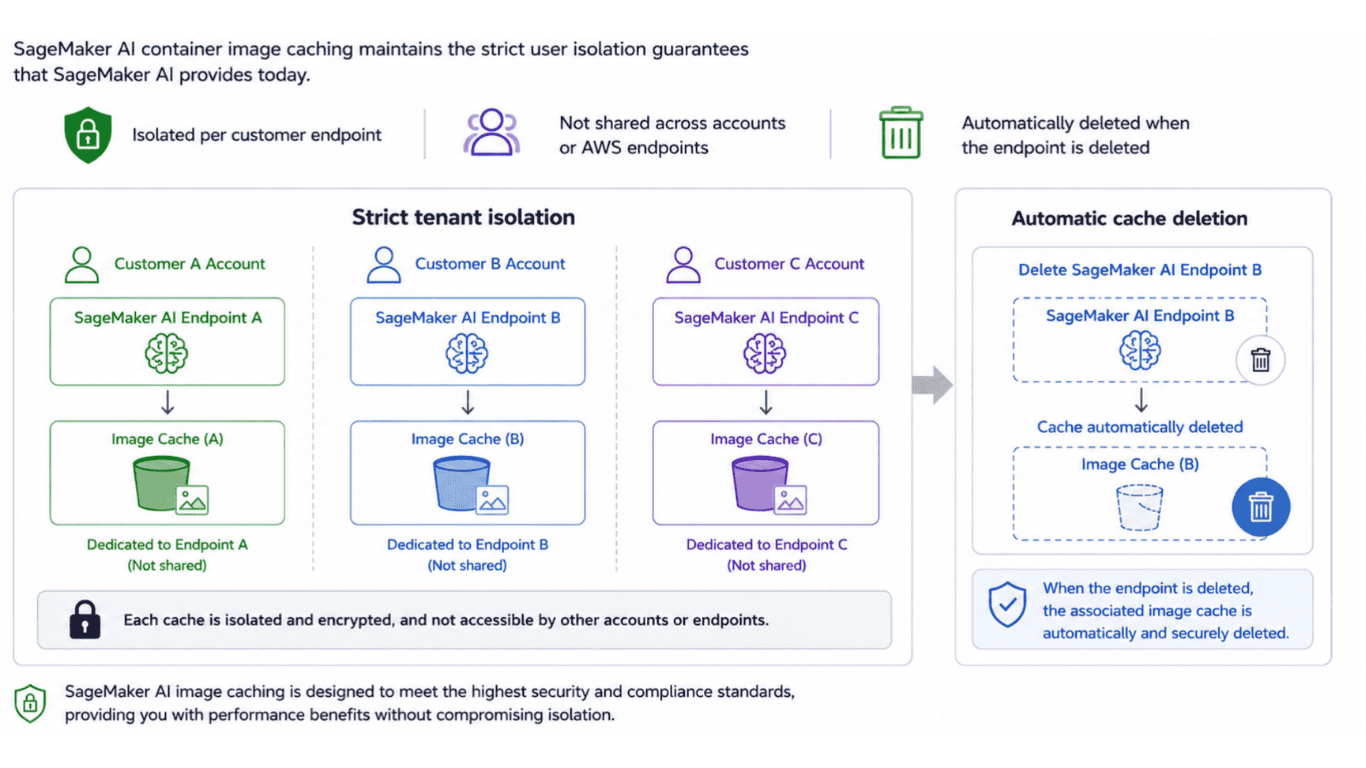
Việc lưu trữ hình ảnh container vào bộ nhớ đệm duy trì các đảm bảo cách ly người dùng nghiêm ngặt mà SageMaker AI hiện đang cung cấp. Mỗi bộ nhớ đệm được dành riêng cho một điểm cuối của khách hàng và không được chia sẻ giữa các tài khoản hoặc điểm cuối AWS. Khi khách hàng xóa điểm cuối SageMaker AI của họ, bộ nhớ đệm hình ảnh liên quan sẽ tự động được xóa.
3. Các cấu hình được hỗ trợ
Tính năng lưu trữ bộ nhớ đệm container được hỗ trợ cho các loại phiên bản tăng tốc trên các điểm cuối suy luận của SageMaker. Nó hoạt động với bất kỳ hình ảnh container nào được lưu trữ trên Amazon ECR, bao gồm cả hình ảnh tùy chỉnh. Không cần sửa đổi container của bạn.
Tính năng lưu trữ bộ nhớ đệm vùng chứa khả dụng tại tất cả các Vùng AWS thương mại hỗ trợ suy luận AI của SageMaker. Để xem danh sách các loại phiên bản và Vùng được hỗ trợ mới nhất, hãy tham khảo tài liệu Amazon SageMaker AI .
4. Phần kết luận
Scale nhanh hơn, vận hành thông minh hơn cùng OSAM! Việc tối ưu hóa độ trễ với SageMaker Container Caching không chỉ mang lại trải nghiệm xuất sắc cho người dùng mà còn là bài toán tối ưu chi phí hạ tầng (FinOps) hiệu quả. Tự hào là Đối tác ủy quyền của AWS, OSAM cung cấp các giải pháp “đo ni đóng giày” để hệ thống AI của bạn vừa đáp ứng lưu lượng khổng lồ, vừa tối ưu hóa ngân sách chặt chẽ.
📌 Tìm hiểu thêm về năng lực triển khai AWS của chúng tôi tại: Dịch vụ Managed Services của OSAM
Để bắt đầu, hãy triển khai khối lượng công việc AI tạo sinh của bạn đến điểm cuối suy luận SageMaker AI trên loại phiên bản tăng tốc được hỗ trợ. Bộ nhớ đệm vùng chứa sẽ tự động được kích hoạt. Để tìm hiểu thêm về các loại phiên bản và Khu vực được hỗ trợ, hãy xem tài liệu Amazon SageMaker AI . Bạn cũng có thể thử Bảng điều khiển quản lý AWS để tạo hoặc cập nhật các điểm cuối của mình.
Trong thời gian tới, chúng tôi sẽ tiếp tục đầu tư để giảm độ trễ khi mở rộng quy mô hơn nữa. Hãy chờ xem.
📩 Liên hệ ngay với OSAM hôm nay để được đội ngũ chuyên gia tư vấn dịch vụ, đánh giá hệ thống MIỄN PHÍ và hỗ trợ triển khai từ A – Z!
📍 Địa chỉ: Tòa nhà Cloudino, 4/3 Phố Nghĩa Đô, Cầu Giấy, Hà Nội.
🌐 Website: https://osam.io/
📧 Email: marketing.team@osam.cloud
☎️ Hotline: 0242 124 4844



